NiFi の Elasticsearch 7.x 対応奮闘記
04 Dec 2020 | NiFi, Elasticsearchあいやー、2018年でブログ更新止まってるじゃないすか!と気づいたのが、 アドベントカレンダーに参加した一番のメリットでしょうか。。という訳で、この記事は Elasticsearch アドベントカレンダー の 12/4 の記事でございます。 Elasticsearch と Apach NiFi について!
データだけでなく、キャリアの道もつないでくれた NiFi
NiFi というのはシステム間のデータ連携を行うデータフローを構築、運用管理するためのオープンソースプロジェクトです。 Web ブラウザから直感的にデータフローのグラフを操作できるのが便利ですね、多種多様なデータソースに対応しています。
そんな NiFi の開発をするきっかけになったのは、前前職の Coucnbase を広めるためという目的でした。その後ご縁があり NiFi 開発メンバが多く在籍する Cloudera (当時は Hortonworks) に転職。 それから 4年弱、 NiFi の開発者として家に籠もってカリカリコードを書いていたのですが、人との直接的なやりとりが恋しくなり、 Elastic でトレーニング講師の募集を見て面白そうだなーと思い転職、現在は Elastic の Education Engineer として一年を経過したところです。
Elasticsearch は様々なデータソースから発生するログやメトリックなどのデータを蓄積し分析するためのプラットフォームでもよく使われます。 そんな環境の中でデータパイプラインを構築する際に、 NiFi で培ったデータ連携のノウハウや Kafka などのメッセージングシステム、色々なクラウドサービスとの連携などの経験は非常に役立っていると思います。
そして今日、 Elasticsearch 向けのアドベントカレンダーの題材として NiFi と Elasticsearch の連携の話を書いてみようと思った訳です。
やっとこさ NiFi が Elasticsearch 7.x に対応
NiFi ではデータフローを構成する部品としてプロセッサがあります。 Elasticsearch などのデータソースと連携するために PutElasticsearch や FetchElasticsearch などのプロセッサが色々あるのですが、これが Elasticsearch 7.x に対応できていない問題が発生していました。
NIFI-6403 ElasticSearch field selection broken in Elastic 7.0+ で報告されている通り、 _souce_exclude や _source_include が 7.0 から _source_excludes など他の API と形式を揃えるために複数形の名称に変更されたのが原因です。パラメータ名を揃えるために。。なかなかアグレッシブな breaking change っすね。
NiFi のプロセッサでもそれに追随すれば良いのですが、色々と考慮しないといけないことがある訳です。主な問題は以下の二つ:
- NiFi を使っているユーザの Elasticsearch バージョンは 7.x とは限らない
- Elasticsearch 向けのプロセッサが乱立している
一つ目は色々なデータソースを繋ぐ NiFi ならではの問題かもしれません。 極端な話、 Elasticsearch 2.x と、 5.x と 6.x と 7.x を一つの NiFi データフローで利用している方もいるかもしれないのです。 また、そのように複数のバージョンが混在する環境でデータをやりとりする仕組みとして NiFi はとても便利です。 NiFi では各モジュールでバージョンの互換性の壁を超えるために、例えば Kafka だったら ConsumeKafka_1_0、ConsumeKafka_2_0 の様に各バージョン向けのプロセッサを分けてクラスローダも分離して対応することがあります。 Elasticsearch のプロセッサもその様にはっきり分かれていれば簡単だったのですが、プロセッサが乱立していたのです。 Elasticsearch クライアントが元々 REST API を使うものと、 Transport プロトコルを使うものと二種類あったのが、 REST 推奨になった経緯も影響してますね。
これらの問題を解決するためにプルリクエストがいくつか送られ、私もレビューに参加したのですが、なかなかごちゃごちゃしてました。 プロセッサの一覧と、対象の Elasticsearch バージョン、そして NIFI-6403 と NIFI-6404 (ドキュメントの type 指定を必須じゃなくする) を解決する PR #4667 をレビューする際にテストした結果を表にまとめてみましょう:
| Processor | 対象 ES ver | 5.6 | 6.8 | 7.10 |
|---|---|---|---|---|
| PutElasticsearchHttp | 5.0+ | OK | OK | OK |
| PutElasticsearchHttpRecord | 5.0+ | OK | OK | OK |
| FetchElasticsearchHttp | 5.0+ | OK | OK | NG -> OK 注1 |
| QueryElasticsearchHttp | 5.0+ | OK | OK | NG -> OK 注1 |
| ScrollElasticsearchHttp | 5.0+ | OK | OK | NG -> OK 注1 |
| DeleteByQueryElasticsearch | 5.0+ | OK | OK | OK |
| JsonQueryElasticsearch | 5.0+ | OK | OK | OK |
| PutElasticsearchRecord | 5.0+ | OK | OK? 注2 | OK |
| Put, Fetch, DeleteElasticsearch5 注3 | 5.x | - | - | - |
| Fetch, PutElasticsearch | 2.x | - | - | - |
注釈:
- これが NIFI-6403 で対応された部分です。これらのプロセッサで Elasticsearch から取得するフィールドを指定すると
_source_includeAPI パラメータの名前がもう使えなくなっているのでエラーになってしまっていた訳ですね。 - 6.8 へアップグレードする際にフルクラスタリスタートが必要だったのですが、 Http 系プロセッサはリトライに FlowFile をうまく回してくれてデータロスはありませんでしたが、 PutElasticsearchRecord は
failureリレーションシップに FlowFile をルーティングしてしまいました。これではデータロスが発生してしまいます。 NIFI-8048 で対応しました。 - 実は Elasticsearch 5.x 向けのプロセッサが存在します。しかしこれらは今は推奨されなくなった Transport プロトコルを使ったクライアント実装でもあり、他のプロセッサで代替えが効くため、デフォルトのビルドからは対象外となりました。NIFI-7604
PR #4667 が適用されたあとは上記表の様にそれぞれ対象の Elasticsearch バージョンと問題なく連携が可能になっています。
テストはパッチ適用前と後で、5.6 から 7.10 までのアップグレードシナリオをテストしました。 アップグレードの際は NiFi のデータフローは止めずに、レジリエントな実装になっているかも確認してみました。
Elasticsearch 5.0 以上で利用可能なプロセッサは XXXElasticsearchHttp 系のものと XXXElasticsearch 系の二種類があります。
Http 系のプロセッサは OkHttp を利用しており、 HTTP のリクエストに送信する JSON ペイロードを Java コード内で直接構築しています。
XXXElasticsearch 系の方は elasticsearch-rest-client-5.6.16 を使っています。
7.0 の breaking change で影響があったのはリクエストの JSON を独自に作成していたからなんですね。
気付き
今回のプルリクエストレビューを通して色々な気付きがありました:
- NiFi で全てのキューを空っぽにする ‘Empty all queues’ という操作が可能になってました!これはテストの時めちゃくちゃ便利です。
- ScrollElasticsearchHttp は不思議なプロセッサです。大量のドキュメントをデータベースのカーソルみたいな仕組みで数回に分けて取得できます。一回のスクロールが終わると、終わったことをプロセッサのステートに記録して、その後は何にもしません。そういう設計です。 NiFi プロセッサの中では珍しい「一発屋さん」です。
- レジリエンシー!テストではアップグレード中にもデータ更新やクエリを NiFi から実行し続けてみました。 Kibana からアップグレードアシスタンスを実行する時にインデックスをクローズして新しいマッピングのものに切り替えて、という手順が必要なのですが、その間でも NiFi のリトライキューに更新リクエストが上手く溜まって、アップグレードが終わったらちゃんと Elasticsearch に登録されていました。 NiFi ありがたや。
- プロセッサの設定で
upsertというのがあり、 Elasticsearch の CRUD 操作で単純にドキュメントを PUT/POST したら常にupsertなんじゃないの?と他のデータベースでの insert or update 的な解釈で upsert を捉えていたので、不思議に思いドキュメントを読んだら、 Update API のパラメータで upsert というのがあるんですね。初めて知りました。これは対象ドキュメントがいる場合はスクリプトでドキュメントを加工して、いない場合は upsert で指定したドキュメントを初期値とする機能です! - Elasticsearch は Elasticsearch Service を使ってテストしました。アップグレード簡単ですもん。全てのアップグレードをローリングアップグレードで行いたかったのですが、5.x から 6.x ではたとえ 5.6 からのアップグレードであっても ESS の場合必ずフルクラスタリスタートが必要になるみたいです。ドキュメントにも記載あり。 “In version 6.x, TLS between Elasticsearch cluster nodes is always enabled on Elasticsearch Service. To enable internal TLS between cluster nodes, Elasticsearch cluster must perform a full cluster restart on Elasticsearch Service, even if you are upgrading from version 5.6.”
- Kibana の画面、めっちゃ変わったよね!
久々にプルリク送信!
Elasticsearch の 5.6 から 6.8 へのアップグレード時にフルクラスタリスタートが必要だったのですが、 PutElasticsearchRecord はリスタート中に FlowFile を retry ではなく failure にルーティングしてしまいました。
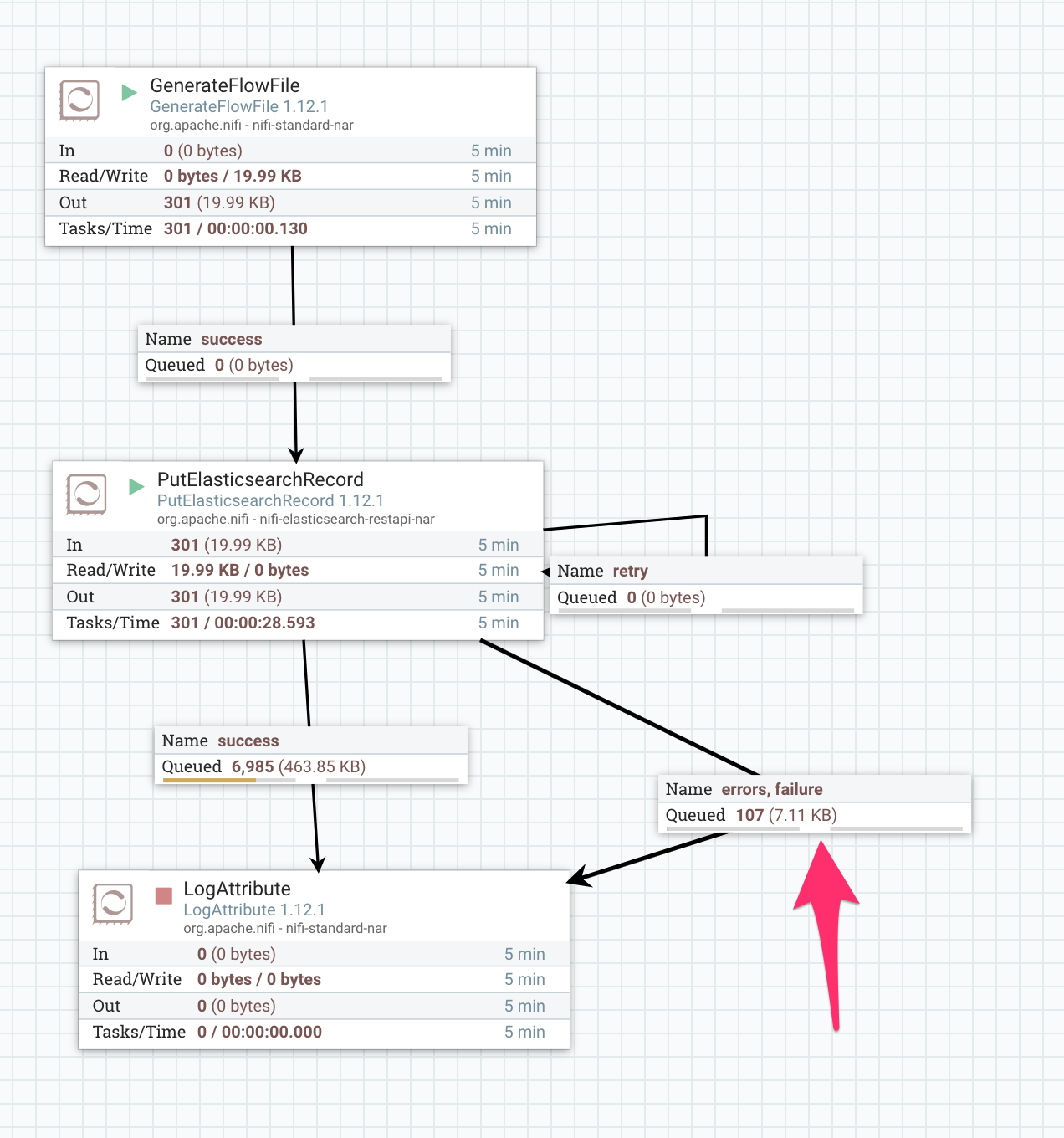
このプロセッサではリトライ可能かどうかの判定を発生した例外のクラス名で判断していたのですが、以下の例外は想定されていなかった様子です。 ステータスコードは 503 だし、メッセージもメンテナンス、リカバリ中と明示されているのでこれは救ってあげたいですね:
org.apache.nifi.elasticsearch.ElasticsearchError: org.elasticsearch.client.ResponseException: POST https://xxx.found.io:9243/_bulk: HTTP/1.1 503 Service Unavailable
{"ok":false,"message":"Resource is under maintenance / recovery."}
at org.apache.nifi.elasticsearch.ElasticSearchClientServiceImpl.bulk(ElasticSearchClientServiceImpl.java:274)
修正は簡単そうだったので NIFI-8048 を発行してプルリクを投げると翌日すぐにマージされました。やはりこんな感じでオープンソースの開発に関わるのは好奇心そそられて楽しいもんです。 最初はこんがらがってごちゃごちゃに絡まっていた糸が一本一本ほつれて明らかになっていく過程が好き。ほどけないときは物凄いストレスですけど!