Couchbase Connect 15: Kafkaで大規模リアルタイムストリーム
09 Jul 2015 | CouchbaseCouchbase Connect 15のセッション紹介シリーズ、第三弾、今日はConfluentのエンジニア Ewenさん、CouchbaseのPrincipal Solution Engineer, Davidさんによる「Real Time Streams at Scale with Kafka」を紹介します。
Confluentはストリームデータプラットフォームのスタートアップ、LinkedInのKafka開発チームから創設されたとのことです。LinkedInでのノウハウを他の企業でも活かし、リアルタイムストリームとしてエンタープライズなデータに容易にアクセスできるプラットフォームの構築にフォーカスしているとのこと。ConfluentプラットフォームのソースはGitHubで公開されています。Dockerコンテナのイメージもあるので今度是非試してみたいと思います!
Confluentプラットフォームの概要:
- Kafkaのストリーム処理連携
- 共通システム向けのデータストリームコネクタ
- end-to-endのデータフロー監視、真面目にストリーム処理やるならエラーやデータロスの検知が非常に重要!
- スキーマ、メタデータ管理、Avroを利用
- Confluent Platform 1.0がリリースされた
システム内の様々なコンポーネントを連携するためのメッセージングキュー、しかし既存のMQではスループットが足りなかった
Webアプリ、キャッシュ、データベース、DWH、Hadoop、ログ分析、モニタリング … etc 全部つなげるとものすごい複雑になる。 アドホックにシステム連携を開発していくと複雑なアーキテクチャに陥りやすい。 データ変更が他のシステムに与える影響も良く考える必要が出てくる。
データ連携システムの主な課題: “データが最終的にすべての正しい場所に存在させること” すべての正しい場所とは複数のストレージの場合も。
Webアプリから直接キャッシュ、データベース、Hadoopなど様々なストレージにアクセスするとアプリのコードが複雑になる。そもそもHadoopはBatch向けなのでオンラインアプリから直接アクセスするのは現実的ではない。 そのため、MQを間に配置する。MQに一度書き込めば、複数のConsumerから利用できる。 アプリケーションとバックエンドを分離するとアプリのコードも綺麗になる。
最初はActive MQやRabbit MQを試した。が、色々な問題で失敗。 特に、MQは一件一件のメッセージのAck管理などのオーバヘッドが高いため、スループットと永続性で問題が発生。 高頻度の書込みに耐えられないといけない。
Kafkaを中心としたデータ連携は、Hadoop HDFSを中心としたエコシステムと同様に広がっている
Hadoopの魅力的な機能はMapReduceではなく、HDFSだ。 HDFSが様々なツールで共通に利用できるストレージシステムとなった。 HiveやSparkなどでデータを連携できる。 だがしかし、これはリアルタイムなオペレーション向きではない。 リアルタイムな領域でもKAFKAを中心に同じようなことが起きている。
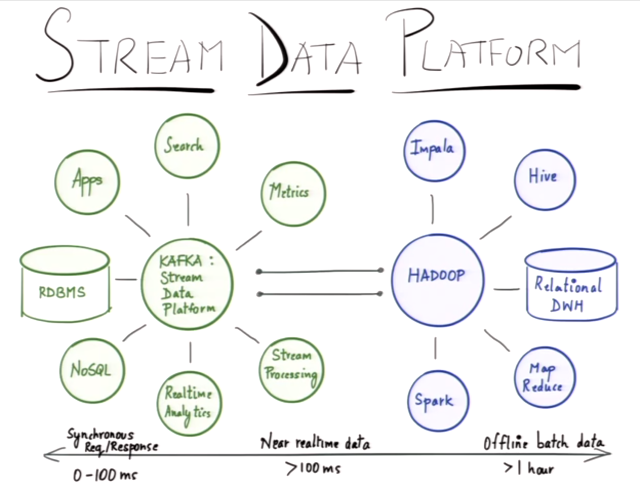
LinkedInをはじめ、多くの企業で使わるKafka
LinkedInは2009年ごろに前述の課題を解決するためにKafkaを開発、本セッションではKafkaが他のMQとどのように異なるのかを解説。 LinkedInでは5000億件のイベント/日を取り込み、複数のConsumer/システムにFan out、2.5兆のメッセージを処理している。 NetflixやUBER, Paypal, verizon, Cisco, salesforceなどいろいろな企業でも使われている。 (Couchbase Serverのユーザ企業も多いですね)
KafkaはメッセージPub/Subキュー、 Producer, Kafka Brokers, Consumerで構成される。
Kafkaはなぜ高性能?
Kafkaのストレージはログ形式、追記型のファイル、シーケンシャルアクセス。 Pub/Subで複数のConsumerが同一のログを消費できる。 タイムベース、データサイズベースでリテンションポリシーが選択できる。 1週間データを残すとか、あるサイズになるまでデータを残すとか。
Kafkaのスケールアウト性
Kafka BrokerがTopicを複数のパーティションに分割、パーティション数、レプリカを設定できる。 Consumerグループ内に複数のConsumerインスタンスを登録して、一つのパーティションは一つのConsumerインスタンスで消費される。
スケールアウトし、データを長期間保存できるため、バッチ層のストレージへのバッファとして利用できる。
Kafkaにその他のミドルを接続することも簡単、Elasticsearchでログ検索とか。 フィルタリング、データ加工、データ集約なども。
ストリーム処理の実装はKafkaのConsumer + カスタムロジック + KafkaのProducerという形になる。 KafkaはSamza, Storm, Spark Streamingなどの処理系のデファクトになりつつある。 Hub & Spokeモデル。
JSONを扱うということは、スキーマがないわけではない。 ソースやシンクでなるべくスキーマを意識しないで済むようにしている。
Couchbase + Kafka
Couchbaseと組み合わせると何がうれしいのか?
- Couchbaseをマスタデータベースとして使う
- トリガ/イベントハンドリング Sessionオブジェクトが期限切れとなったときに何か処理をするなど
- リアルタイムデータ連携
- リアルタイムデータ処理、Couchbaseは非常に高スループットのデータベース
CouchbaseをProducerとして使うこともできる、本セッションのメインテーマ!
CouchbaseのKafka Connector実装
3.0から利用可能になったDCP(Data Change Protocol)を使用している。 DCPはCouchbase Server内部のインデクシング、クラスタ内レプリケーション、クラスタ間レプリケーション(XDCR)で使っている。 DCPのメッセージを受信する、独自のクライアントを実装することもできる。 Java SDKからも接続できるが、オフィシャルにサポートはされていない。
Couchbase Serverがそもそも大量のリクエストを裁くので、DCP Receiver側が追いつかないことがある。そのためバッファが必要になる。 このバッファがずばりKafka! ローレベルで実装するには難しいので、Kafkaコネクタを使うことを推奨。
スライドではDCP Receiverを自前で実装した場合のコードも。 vBucketの数を自分で取得して、、とかなり面倒。
Kafka Producerを使うと、Couchbaseノード、バケット名、パスワード、ZKアドレス、トピック名を指定するだけ。
なぜゴキブリがスライドに居る?? 小説のKafkaからの引用、決してバグがいっぱいあるということではありませんw
デモ
- Kafkaトピックを作成
- Couchbase Producerを使ってDCPストリームを受信
- データ変更メッセージをフィルタリング、メッセージをエンコードして
- Kafka Consumerでstdoutにログ出力
- TwitterデータをCouchbaseに投入、Stdoutにツイートが表示される。
QA
- Producer側でフィルタリングできるのでKafkaに流すデータを絞り込める。
- KafkaとCouchbase Serverは同居させた方が良い? No、パフォーマンス分離のため。Couchbase単体でもAppサーバと分けるのが普通。
- Couchbase Kafka ConnectorはいつGAになるの? 2015/3/4にすでに1.0.0 GAが出ている。
- Confluent側のセキュリティ、認証はどうなってるの? Kafka側で実装が進んでいる。が現在のバージョンではセキュリティは組み込まれていない。Topicへのアクセス制限などもロードマップには上がっている。
- 性能、書込みスループットは? LinkedInのエンジニアブログにあるよ。(検索すると確かにありました、Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines)、ベンチマーク結果だけでなく、”Kafka in 30 seconds”というセクションでKafkaのアーキテクチャ概要が記載されているのが分かりやすくて良いです)
- KafkaではPartitionキーは選択可能、ユーザIDで分けたりできる。
まとめ
ビデオ見ながらメモをつらつら書いた程度なのであまりまとまっていませんが、Kafkaの特徴やCouchbase Serverと連携するとCouchbase Serverへのデータ変更をKafkaに流してあんなことやこんなことができるということを知っていただければ幸いです。
インタラクティブなアプリケーションのデータをCouchbase Serverに保存して、Kafkaと連携、Sparkでストリーム分析した結果をまたCouchbase Serverに保存してオンラインのユーザ体験を向上、など、明るい未来が広がりますね!
一点、注意事項として、3月に1.0.0がリリースされたCouchbase Kafkaコネクタですが、まだ再接続時に前回完了していた場所からDCPストリームの受信を再開するという機能が実装されていません。この機能はver 1.1.0で実装される予定がありますので、気になる方はJIRAのチケットをチェック!