Query WorkbenchでガンガンN1QL! その2
09 Dec 2015 | CouchbaseCouchbase Advent Calendar、12/9分の記事です。昨日に引き続き、N1QLでJSONをいじくり倒す際に便利なQuery Workbenchを紹介します! 第2回目はJSONのスキーマを推測するdescribeについて、こいつは強力です!
ドキュメントをサンプリングしてスキーマを推測するDescribe!
Query Workbenchのドキュメントに記載されているdescribeを試してみましょう!
Support for N1QL describe queries
The query workbench supports a preview of the N1QL describe command. This command infers a “schema” for a bucket by examining a random sample of documents. Because this command is based on a random sample, the results may vary slightly from run to run. The default sample size is 1000 documents. The syntax for the command is:
describe <bucket_name> [ limit <sample size> ]
訳すと、
N1QLの
describeクエリに対応Query WorkbenchはN1QLの
describeコマンドのプレビューに対応している。このコマンドは、ドキュメントのランダムサンプリングを行い、バケットのスキーマを推測する。このコマンドはランダムサンプリングに基づくため、結果は実行するたびに若干異なる場合がある。デフォルトのサンプルサイズは1000ドキュメント。コマンドのシンタックスは:describe <bucket_name> [ limit <sample size> ]
早速サンプルバケットのtravel-sampleに対して実行してみましょう:
describe `travel-sample`;Flavorとして、そのスキーマと識別できる項目と値が推測されます。typeでスキーマが分かれている、というのはCouchbase Server側では全く管理されておらず、ドキュメントをモデリングした開発者のみが知っているはずです。見事に推測されていますね!
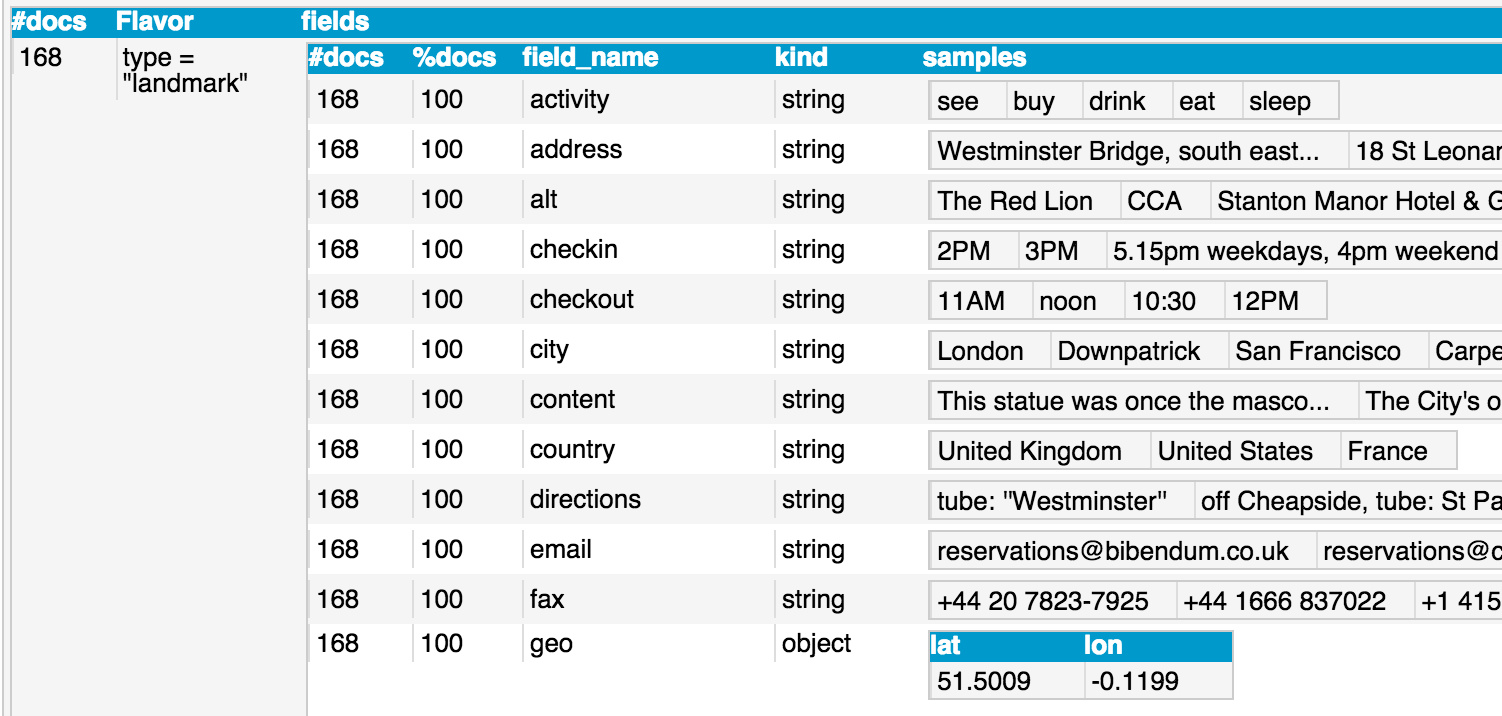
他の結果も見てみましょう。1000件ランダムサンプリングしたドキュメントで、各Flavorが何件あったのかは#docsで分かります。全体の件数からドキュメント分布の傾向を把握するのにも利用できますね。
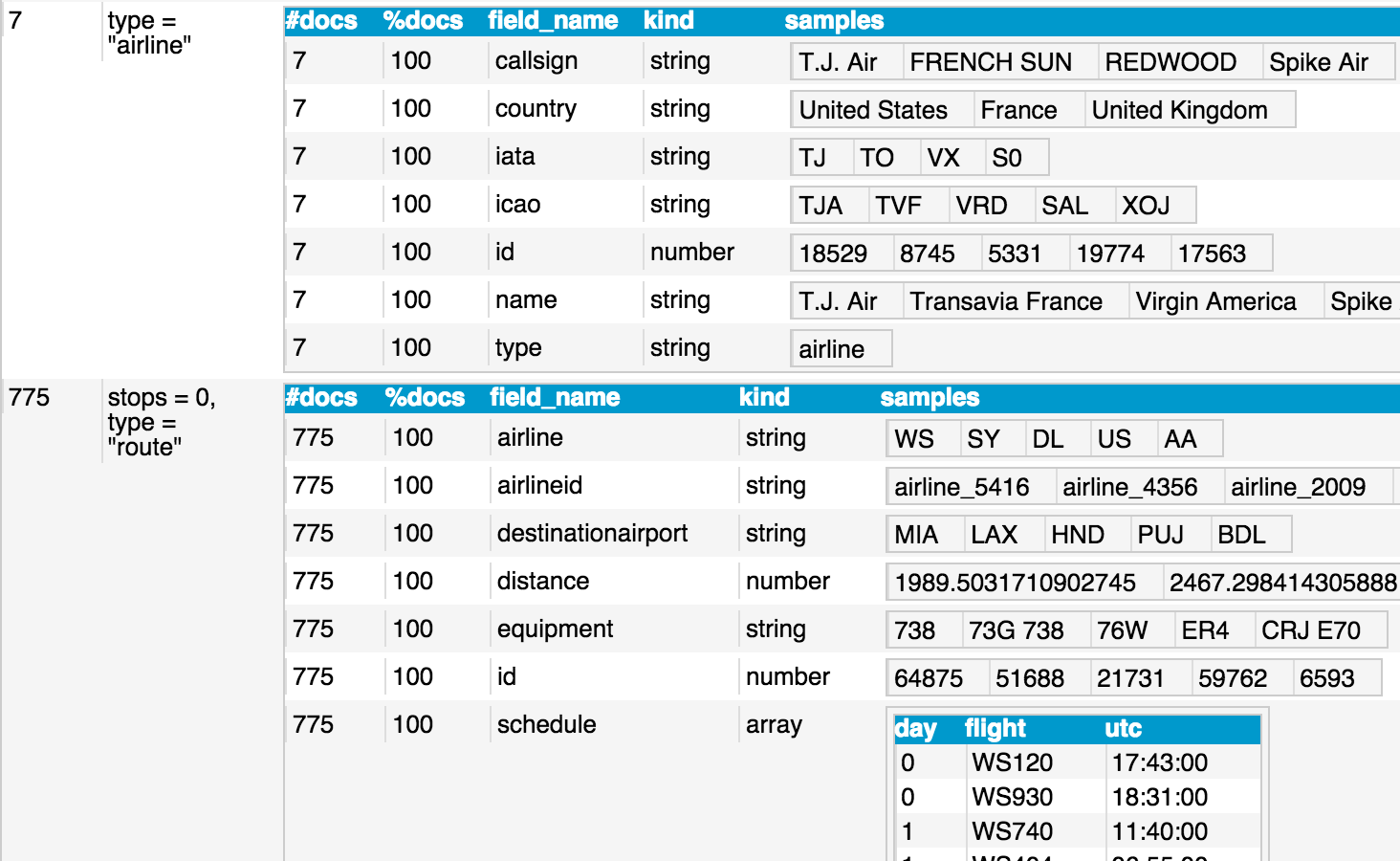
fieldsには、そのスキーマの項目として、どの項目が、何型で、どの程度のドキュメントで定義されているのか、またサンプル値も表示されます。
describeってN1QLの機能なの?
ドキュメントにはdescribeはN1QLの機能のように書いてありましたが、N1QLのシンタックスとして該当の実装はない様子。ui_server.goを見ると、
Proxy function that receives queries from the query UI.
If the query is a normal N1QL query, this function acts as a proxy, passing the query along to cbq-engine, and returns the query result.
If the query is ‘describe’ query, we intercept it and run the describe here, since cbq-engine does not yet support ‘describe’.
まだ、Queryエンジン側でdescribeの実装が終わってないから、describeが実行されたら、UI側で実行するとの記載がありました。
どうやってランダムサンプリングしてるの?
DescribeではJSONドキュメントをランダムサンプリングして推測に利用しています。そもそもドキュメントのキーがわからないのに、どうやってランダムサンプリングできるのか、気になったので実装を調べてみました。
describe_keyspace.goでは、Memcachedのバイナリプロトコルで、0xB6のコマンドを利用しています:
req := &gomemcached.MCRequest{
Opcode: 0xB6,
}
resp, err := kvStores[curKV].Send(req)
if err != nil {
//fmt.Printf("rand error: %v\n", err)
error := map[string]interface{}{"error": fmt.Sprintf("{\"error\":\"Error sampling documents. Either no documents in bucket, or invalid CB version (must be >= CB4.0, not beta).\n%v\"}", err)}
return value.NewValue(error)
}リクエストでエラーが起きると、Couchbase Serverのバージョンが4.0移行でないとこのランダムアクセスは利用できないということが示唆されています。
Memcachedのバイナリプロトコルでは、どんなコマンドがあるのかちょっと気になりますね。コマンドの一覧は、protocol_binary.hで定義されています、4.0で追加されたCMD_GET_RANDOM_KEYもありますね:
/**
* Command that returns cluster configuration
*/
PROTOCOL_BINARY_CMD_GET_CLUSTER_CONFIG = 0xb5,
PROTOCOL_BINARY_CMD_GET_RANDOM_KEY = 0xb6,Flavorって?
describe_keyspace.goでは、GetFlavorsFromCollectionsでスキーマの推測を実行しています。
// 現在のバージョンでは、
// similarityMetricは0.6
// numSampleValuesは5 で固定
flavors := collection.GetFlavorsFromCollection(similarityMetric,numSampleValues)schema.goの先頭のコメントにスキーマ推測の仕組みが詳細に記してあります。Flavorについては、以下の記載がありました:
The similarity metric describes how similar two schemas must be to be merged into a single flavor. It is a value between 0 and 1, indicating the fraction of top level fields that are equal. E.g., a value of 0 would cause every schema to be merged into a single universal flavor. A value of 1.0 would create a different flavor for every distinct schema. I have found that 0.6 to be about the right threshold to handle the Couchbase sample data.
簡単に訳すと、
simirarityの値は二つのスキーマが単一のflavorに集約されるべき類似度を示す。0から1の値であり、トップレベルのフィールドが同一である割合となる。例えば、0の場合、すべてのスキーマが単一の全体で共通のflavorに集約される。1.0の場合、各々のスキーマが個別のflavorを生成することになる。Couchbaseサンプルデータを扱うには0.6が最適な閾値だと判断した。
とあります。また、こんな記述もありました:
The numSampleValues parameter indicates how many sample values should be kept for each field. Sample values can help a user understand the domain of a field, and they are also used in determining what fields only have a single value for a flavor, i.e., as a way of determining invariant fields such as type fields. The flavor name won’t work if this value is set to less than 2.
こちらも簡単に訳すと、
numSampleValuesパラメータは各フィールドにおけるサンプル値の保持数である。 サンプル値はユーザがフィールドのドメインを理解するのを助けると同時に、そのflavorにおいて、どのフィールドが単一の値のみで構成されるのかを特定するのにも利用される。 すなわち、typeフィールドの様な普遍のフィールドを特定する際にである。 Flavor名はこの値が2未満の場合動作しない。
describeはサンプルのJSONのトップレベルフィールドの類似度が0.6以上のものを同一のflavorとしてまとめ、そのflavorの中で普遍のフィールド(全サンプルが同一の値を持つ)ものをflavor nameとして判定してくれるのです!
similarityMetricとnumSampleValuesが指定できないのはちょっと残念ですが、N1QLのstatementとして実装される際には公開されていることを期待しましょう。
まとめ
DescribeはAd-hocなクエリを実行したい場合に事前にスキーマが把握できると非常に助かりますね! 他システムのAPIから取得したJSONをとりあえず突っ込んで、describeでどんな項目があるのか調べてからクエリを実行する場合も便利そうです。
みなさんも是非いろんなデータセットに使ってみてください :)