Apache NiFi and Couchbase Server
02 Oct 2015 | Couchbaseかなり久々の投稿です、本日はApache NiFiプロジェクトとCouchbase Serverの連携について! NiFi面白いです!
- NiFiをご存知でしょうか?
- NiFiとCouchbaseと私
- Process GroupでData Flowを管理しよう
- Couchbase Serverへの接続定義: CouchbaseClusterService
- PutCouchbaseKeyの活用例: TwitterからTweetを取得してCouchbaseに保存する
- GetCouchbaseKeyの活用例: Couchbaseのドキュメントをキー指定で抜き出して単一のZipファイルにまとめる
- まとめ
みなさん、NiFiをご存知でしょうか?
http://www.zdnet.com/article/hortonworks-cto-on-apache-nifi-what-is-it-and-why-does-it-matter-to-iot/
もともとは”Niagara Files”という、National Security Agency (NSA)で8年以上も開発が続けられていたプロジェクトで、現在はオープンソースの“Apache NiFi”としてApache Software FoundationのTop Levelプロジェクトとなっています。
先日、HortonworksがHortonworks Data Flow (HDF)のコアなエンジンとしてNiFiを採用したことが話題になりました。
- セキュリティ
- データの双方向性
- サーバ間のデータ転送
- スケーラブル
上記の特徴を持ち合わせ、HDFではIoTソリューションでの重要なコンポーネントとして動作します。 NiFi自体もクラスタリング構成でスケールアウトすることができます。
NiFiはダウンロードして起動すると、WebブラウザからGUIによるデータフローの定義画面が利用できます。 幾つかNiFiを理解する上で重要なキーワードを説明しておきます:
- FlowFile: NiFiの処理中で、データはすべてFlowFileというオブジェクトでやりとりされます、FlowFileは不透明なコンテンツと、Attributeと呼ばれる任意の属性値を持っています、まさにファイルですね
- Processor: データフロー内で処理を実行する小粒のモジュールです、Linuxのコマンドみたいに、一つのことをうまくやる、という感じで実装されています、現在、HTTPやDatabaseアクセスなど、80弱のコンポーネントが用意されています
- Relationship: 各Processorの間をつなげるパイプです、Processorによっては、success, failure, originalなど複数のRelationshipを持っています、処理したFlowFileを次のProcessorへと転送する道筋となります
NiFiとCouchbaseと私
なぜ、今回CouchbaseとNiFiのブログポストを書こうかと思ったかと言うと。。。
「私が書いたコードが初めてASFのTop Level Projectのコードベースに取り込まれた!!」
からです、嬉しくて大興奮 (>_<)
プロジェクトへの貢献の過程はこちらをご覧ください、興味があれば(笑)
- JIRA: NIFI-992: Couchbase Server Processors
- Pull Request: NIFI-992: Adding nifi-couchbase-bundle
私のつたないJavaソースコードも、親切丁寧にレビューしていただき、本当に勉強になりました! それでは、NiFiのサンプルと共に、NiFiとCouchbase Serverがどのように協調動作するのかを解説いたします、えっへん。
Process GroupでData Flowを管理しよう
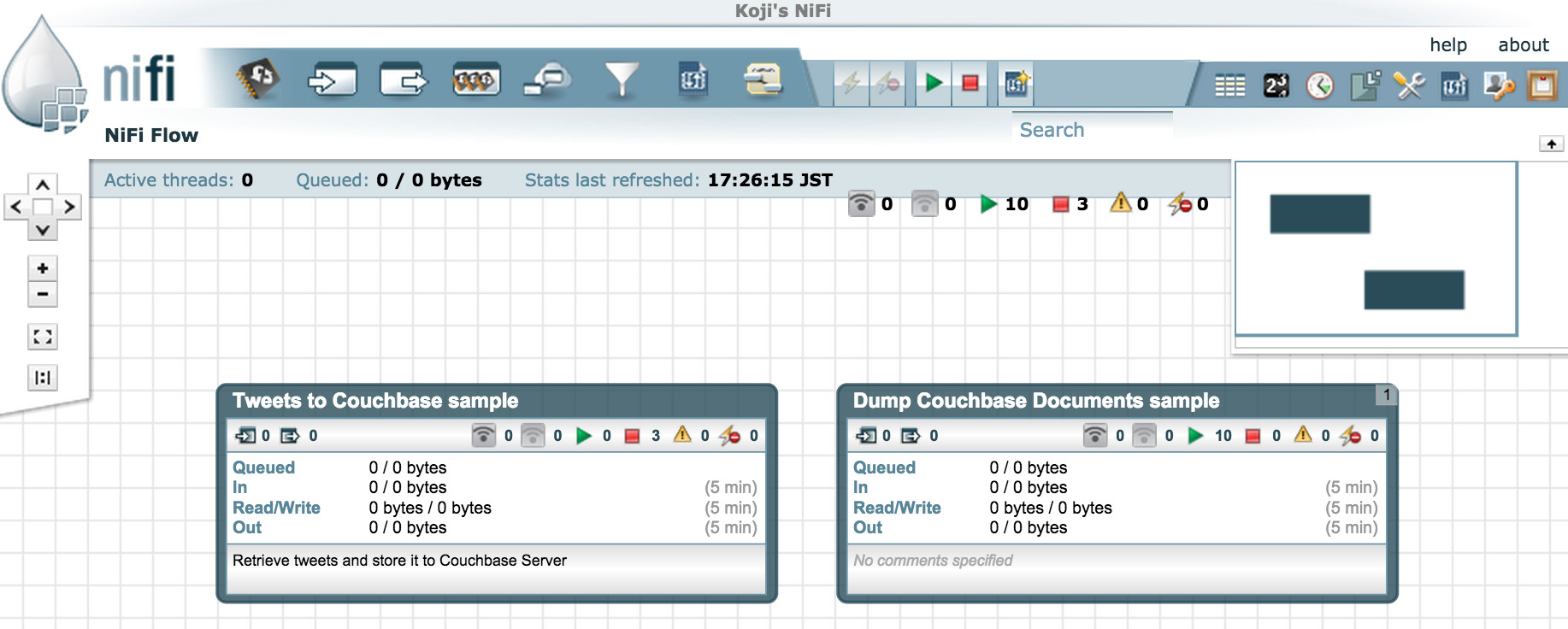
NiFiのData Flowを作成する場合、一連の流れをProcess Groupでまとめて管理すると便利です。 グループ単位で起動や停止ができますし、何よりわかりやすいですね!
今回は二つのグループを定義して、PutCouchbaseKeyとGetCouchbaseKeyでどんなことができるのかをご説明しましょう :)
Couchbase Serverへの接続定義: CouchbaseClusterService
実際のData Flowの説明に入る前に、どのようにCouchbase Serverへの接続設定を定義しているのかを説明しておきます。
NiFiのData Flowでは、各Processorから利用する共通のコンポーネントをControlller Serviceとして定義できます。 この仕組みを利用してCouchbaseクラスタへの接続定義をController Serviceとして集中管理できるようにしています。 他にもRDBMSへの接続プールを管理するController Serviceなどもあります。
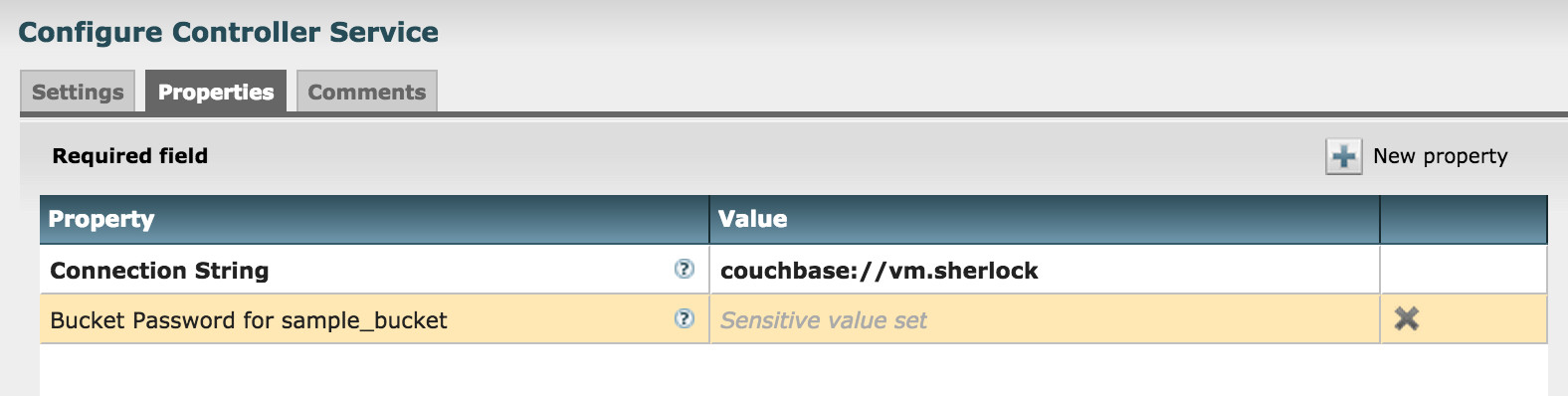
バケットにパスワードが設定されている場合、ここでパスワードを指定します。
一度Controller Serviceとして接続定義を行えば、各Processorでは参照するバケット名を指定するだけで良いようになっています。 一つのData Flow内で複数のクラスタを参照する場合、それぞれのController Serviceを定義します。 接続する先が変わっても、ここの設定を変えるだけで済むので楽ですね。
PutCouchbaseKeyの活用例: TwitterからTweetを取得してCouchbaseに保存する
非常にありがちなサンプルですが、TwitterからTweetを取得してJSONの結果をCouchbase Serverへと保存してみましょう。
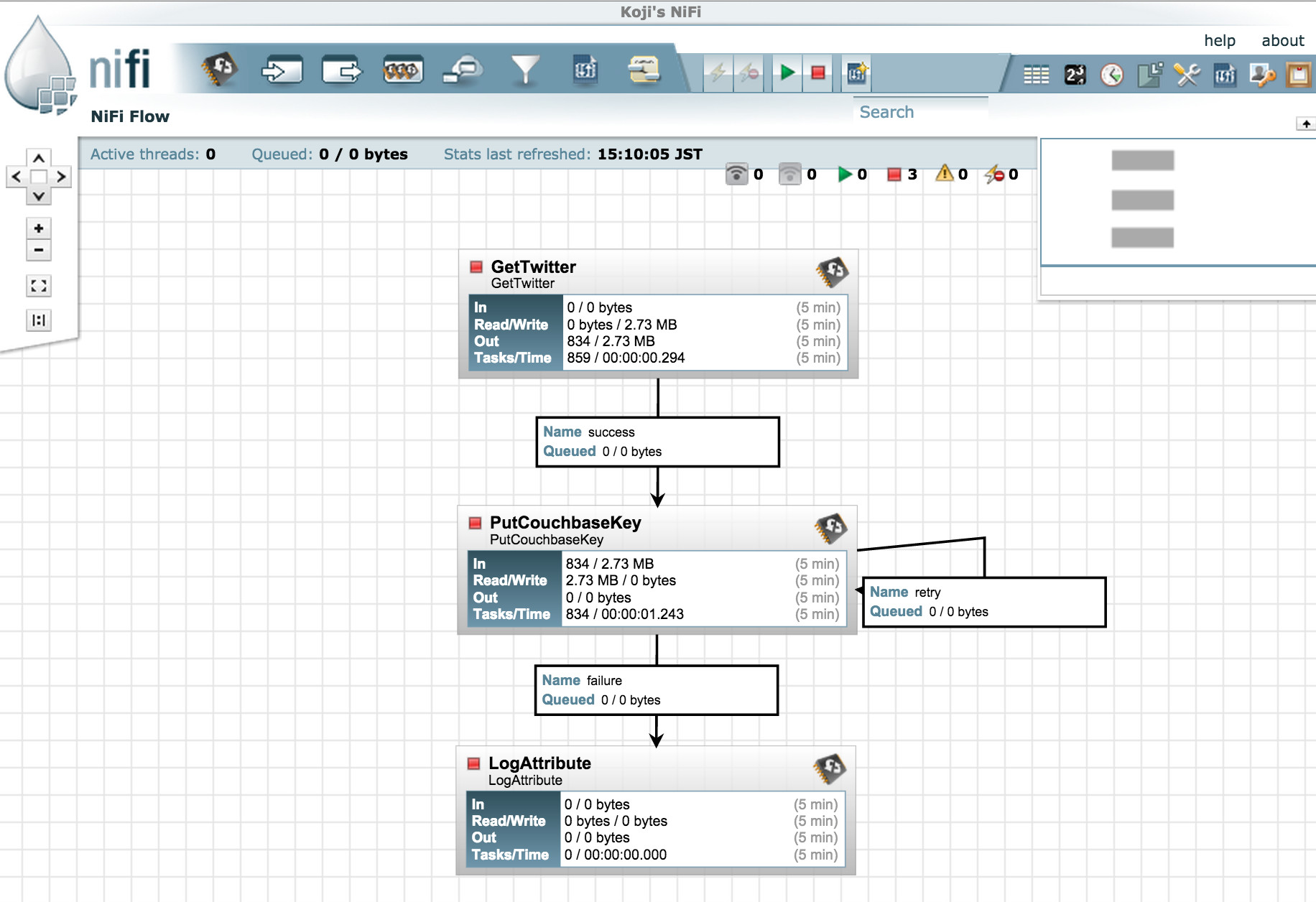
GetTwitter: NiFiにはこのように便利なProcessorが多数あり、他システムとのデータ連携が容易に実装できますPutCouchbaseKey: Tweetが一件ずつFlowFileとして渡ってくるので、FlowFileのUUIDをCouchbaseのドキュメントIdとしてCouchbaseへ格納します、このProcessorからは自身へのRelationshipとしてretryをつなげています、Couchbaseへの保存時にリトライで成功する可能性のあるエラーは、retryに回されますLogAttribute: PutCouchbaseKeyでは、保存した結果のCASやExpiryをFlowFileのAttributeに設定して次のProcessorへと転送します、LogAttributeはこのようにAttributeやFlowFileの内容をログに出力するのに便利です
PutCouchbaseKeyの設定項目を見てみましょう:
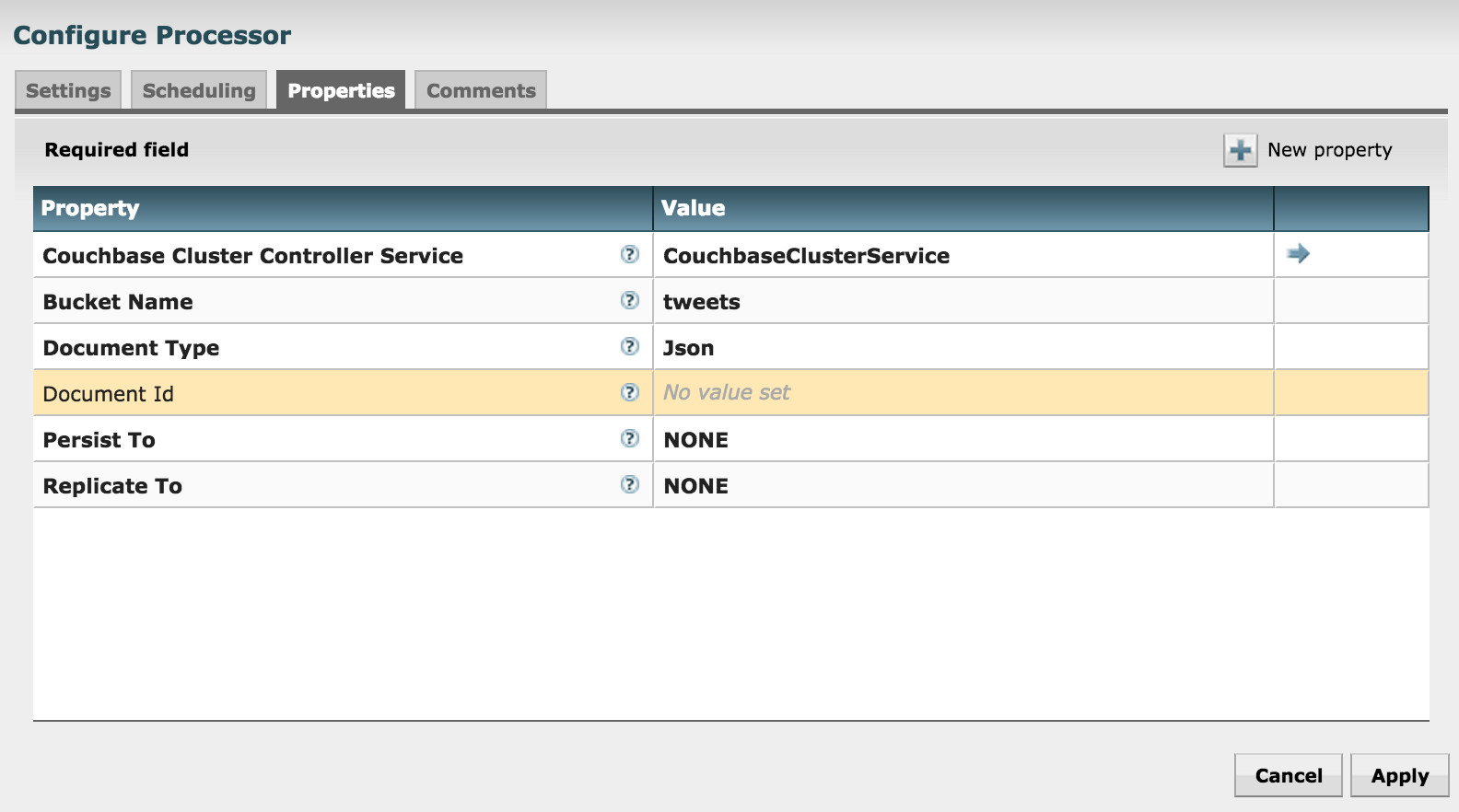
- Couchbase Cluster Controller Serviceで、Couchbaseへの接続を一元管理しているController Serviceを指定します
- Bucket NameでJSONドキュメントを保存するバケット名を指定します
- Document Typeでは、JsonかBinaryかを指定します
- Persist ToとReplicate Toで、書き込みオペレーションの信頼度を設定します、言わずもがな、これらはパフォーマンスとのトレードオフです
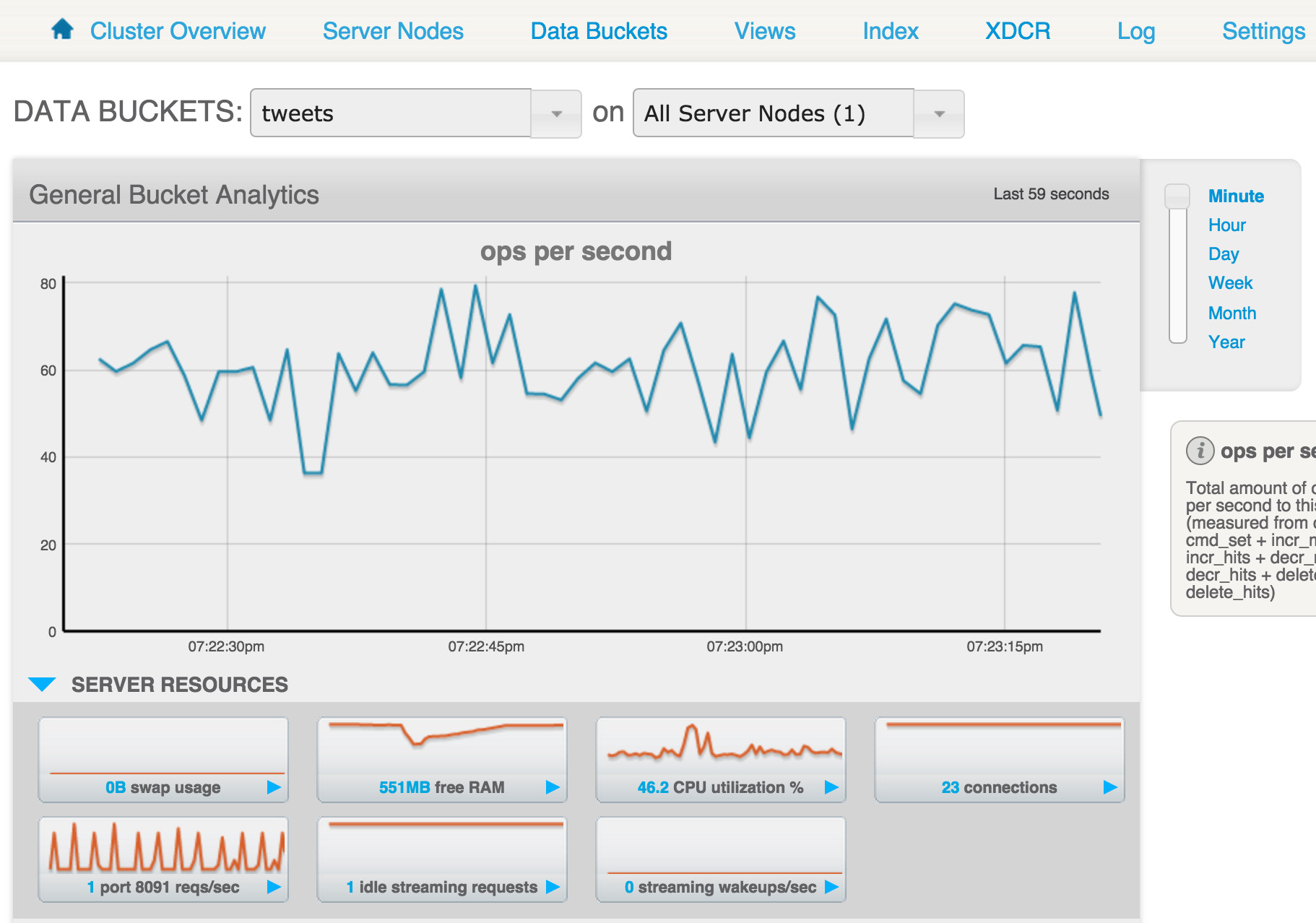
さぁ、NiFiのData Flowを実行してみましょう! 方法は簡単、緑の三角をクリックするだけです! Couchbase Serverの管理画面を見ると、NiFiからTweetのデータが保存されている様子がわかります。
GetCouchbaseKeyの活用例: Couchbaseのドキュメントをキー指定で抜き出して単一のZipファイルにまとめる
簡易的なバックアップとか、毎日更新される特定のドキュメントを定期的に取得したり、他のシステムにアップロードするためのドキュメントをダンプしたりといった利用例が想定できます。
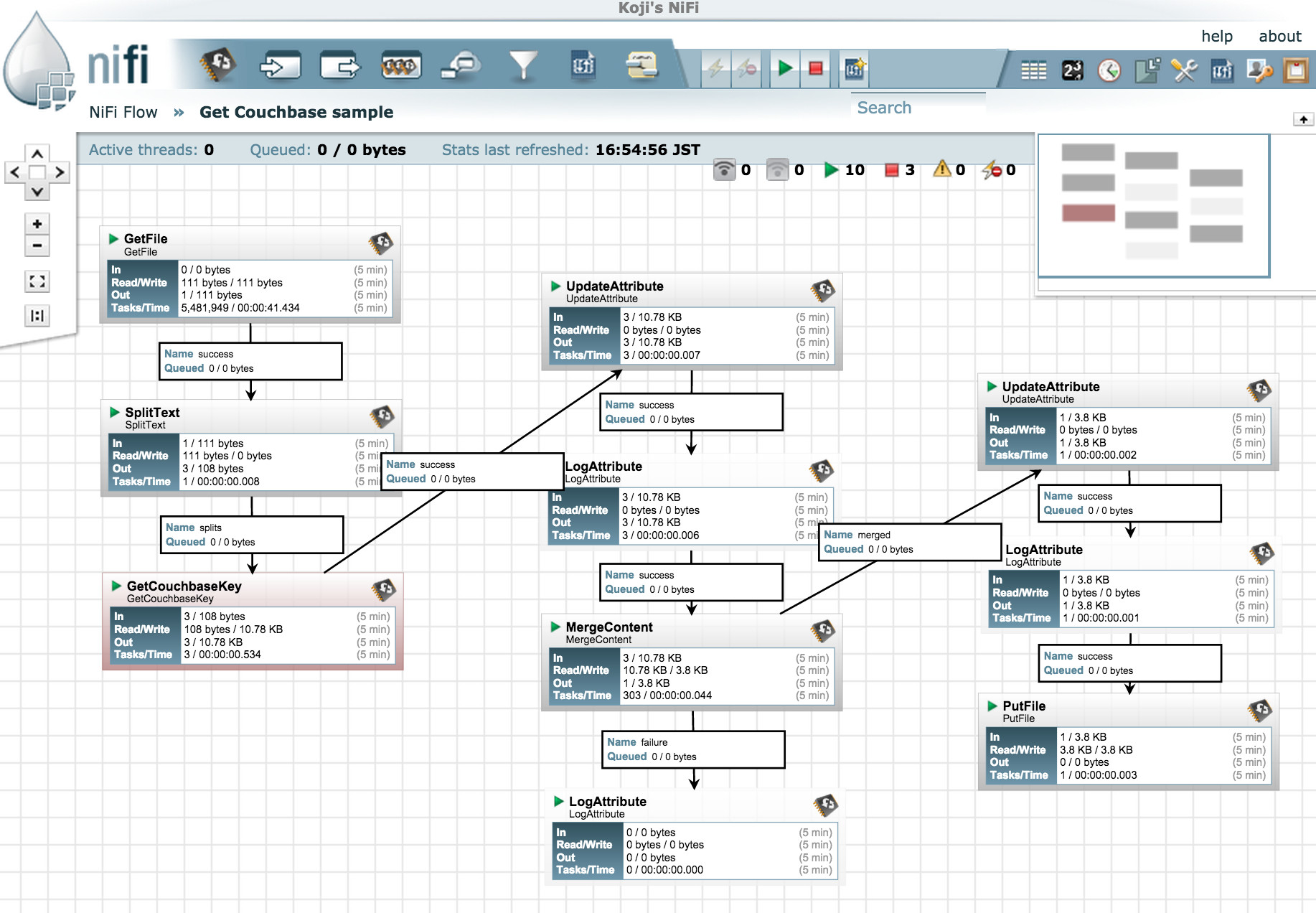
以下がData Flowのサンプルになりますが、先ほどのPutCouchbaseKeyの例よりも多様なProcessorが登場しています。
一つずつ解説していきましょう(LogAttributeは割愛):
GetFile: 指定ディレクトリを監視して、ダンプするCouchbaseドキュメントのIdを複数記載したファイルを読み込みますSplitText: 読み込んだファイルを改行コードでFlowFileに分割しますGetCouchbaseKey: 渡ってきたFlowFile内のテキストをIdとしてCouchbaseからドキュメントをGetしますUpdateAttribute: filenameを${‘couchbase.doc.id’}のExpressionでCouchbaseのドキュメントIDとします、これがZipファイル内に保存されるファイル名となりますMergeContent: 複数のFlowFileを一つのZipファイルに圧縮しますUpdateAttribute: filenameを現在の日時で設定します、Expressionは${now():format(‘yyyyMMdd_HHmmss’)}.zipPutFile: 最後に、作成されたZipのFloFileを指定したディレクトリに保存します
実際のディレクトリと入出力ファイルは以下のようになっています:
# 読み込むDocumentのIDをファイルに記述する
koji@Kojis-MacBook-Pro:tmp$ cat in.dat
000069ee-cf4d-46bb-a11d-de09a00cd82c
00021100-bb6c-4327-8cad-16474f5cd928
0004b561-1ea4-4e46-8455-2040481d638e
# 実行環境のディレクトリ構造
drwxr-xr-x 2 koji wheel 68B Oct 2 16:19 couchbase-dump-in/
drwxr-xr-x 2 koji wheel 68B Oct 2 16:29 couchbase-dump-out/
-rw-r--r-- 1 koji wheel 111B Oct 2 16:25 in.dat
# GetFileでは再読込防止のため、オリジナルのファイルを削除するので
# 別ディレクトリでファイルを作成してから、配置するのがオススメ。
# (オプションでオリジナルを残すこともできる)
koji@Kojis-MacBook-Pro:tmp$ cp in.dat couchbase-dump-in/
koji@Kojis-MacBook-Pro:tmp$ ll couchbase-dump-out/
total 8
-rw-r--r-- 1 koji wheel 3.8K Oct 2 16:51 20151002_165136.zip
# NiFiにて作成されたZipファイルを展開してみる
koji@Kojis-MacBook-Pro:couchbase-dump-out$ unzip 20151002_165136.zip
Archive: 20151002_165136.zip
inflating: 000069ee-cf4d-46bb-a11d-de09a00cd82c
inflating: 00021100-bb6c-4327-8cad-16474f5cd928
inflating: 0004b561-1ea4-4e46-8455-2040481d638e
# Zipの中にはCouchbaseから取得したJSONがDocumentのIDをファイル名として保存されている
koji@Kojis-MacBook-Pro:couchbase-dump-out$ ll -h
total 48
-rw-r--r-- 1 koji wheel 156B Oct 2 16:51 000069ee-cf4d-46bb-a11d-de09a00cd82c
-rw-r--r-- 1 koji wheel 2.2K Oct 2 16:51 00021100-bb6c-4327-8cad-16474f5cd928
-rw-r--r-- 1 koji wheel 8.4K Oct 2 16:51 0004b561-1ea4-4e46-8455-2040481d638e
-rw-r--r-- 1 koji wheel 3.8K Oct 2 16:51 20151002_165136.zipGetCouchbaseKeyの設定項目を見てみましょう:
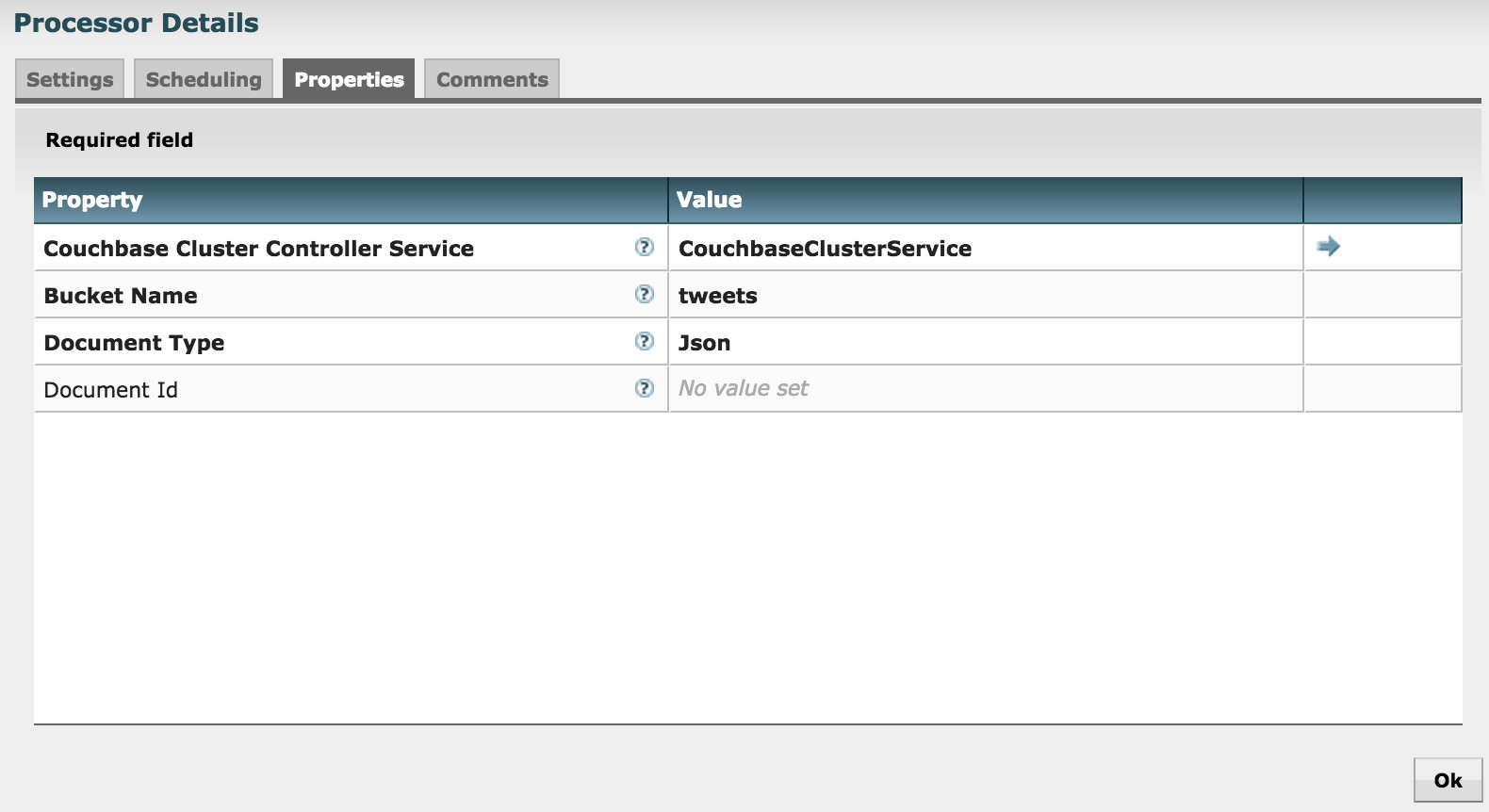
- PutCouchbaseKeyと同様、Couchbaseへの接続はControllerServiceを利用します
- Bucket Nameでドキュメントを取得するバケット名を指定します
- Document TypeではJson/Binaryのいずれかを指定します
- 今回は入力のDataFlowのコンテンツをドキュメントIDとして利用するので空欄のままですが、Document Idに任意の値を設定できます、Expressionを指定して、AttributeからIdを作成することもできます
プログラムを一切書かずに、このような処理が自動化できるのは楽ちんですね!
他のAttributeもファイルに出力したい場合は、ReplaceTextも組み合わせると良いでしょう:
- Regular Expression:
^(.*)$ - Replacement Value:
{"content": $1, "other_attribute": "${'other_attribute'}"}
上記のようにすれば、任意のAttributeをJSONの中に埋め込んでファイルに保存できます。
まとめ
今回はNiFiからCouchbase Serverのデータへアクセスする方法やサンプルのデータフローをご紹介しました。 まだCouchbaseのProcessorは単純なKey/Valueアクセスしか実装していませんが、今後ViewやN1QLを利用できるProcessorも開発していく予定です。乞うご期待!!